
I am currently a joint Ph.D. candidate of Shanghai Jiao Tong University and Monash University from SEIEE since 2022, working with Prof. Weiyao Lin and Prof. Mehrtash Harandi. Before that, I spent 4 wonderful years studying at Huazhong University of Science and Technology as an undergraduate student since 2018 (top 5%). My research interests lie in visual generation, visual understanding, and noise learning, with a particular focus on Diffusion Transformer (DiT). Currently, my work centers on Unified Visual Generation and Understanding with DiT, aiming to overcome the long-standing disconnect between these two tasks and enable them to mutually enhance each other.
If you are interested in my work, please contact me via ganchaofan@sjtu.edu.cn.
🎯 Research Interests
- Diffusion Transformers: Visual Generation and Representation Learning with DiTs, et al.
- Image/Video Understanding: Multimodal Large Models, et al.
- Noise Learning: Self-supervised Semantics Discovery, et al.
🔥 News
- 2025.9: 🎉🎉 1 first-author NeurIPS is accepted!
- 2024.10: ✈️✈️ I will attend ACMMM conference in Melbourne in Oct. Looking forward to seeing old/new friends!
- 2024.9: 🎉🎉 1 NeurIPS(Spotlight) is accepted!
- 2024.7: 🎉🎉 1 first-author ACMMM is accepted!
📝 Selected Projects
📦 Diffusion Transformers

Chaofan Gan,Zicheng Zhao, Yuanpeng Tu, Xi Chen, Ziran Qin, Tieyuan Chen, Yuxi Li, Mehrtash Harandi, Weiyao Lin
ARXIV 2025, preprint
- Massive Activations Drive Fine-Grained Local Detail Synthesis in DiTs.
- Detail Guidance: Superior Local Detail Fidelity Compared to CFG.
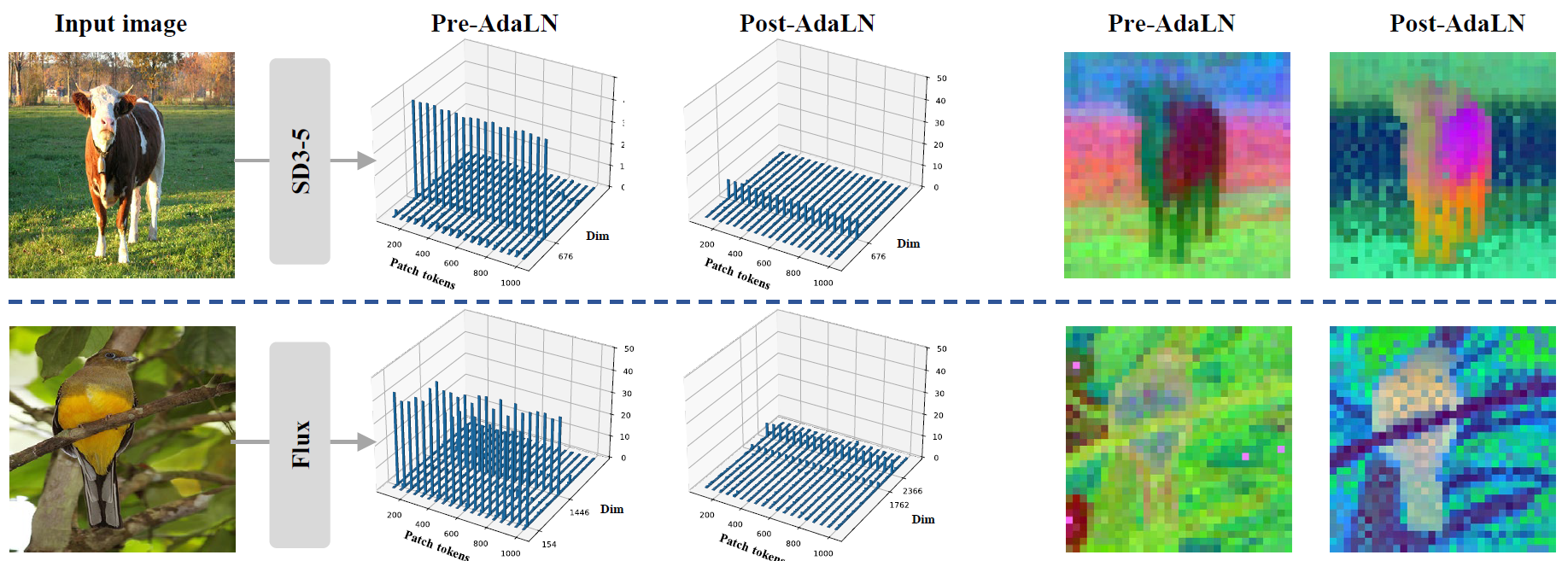
Chaofan Gan, Yuanpeng Tu, Xi Chen, Tieyuan Chen, Yuxi Li, Mehrtash Harandi, Weiyao Lin
Neural Information Processing Systems (NeurIPS), 2025
- Employ Diffusion Transformers as a feature extrator for visual correspondence!
🥑 Noise Learning
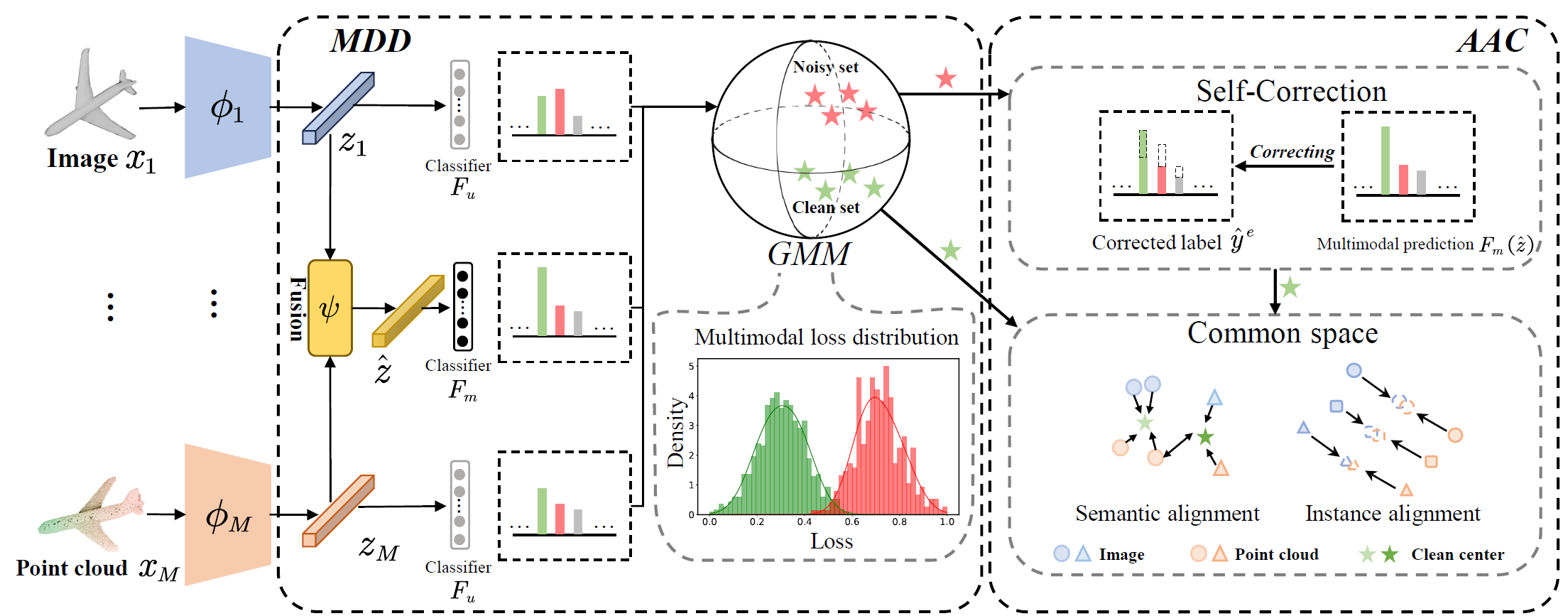
Chaofan Gan, Yuanpeng Tu, Yuxi Li, Weiyao Lin
ACM International Conference on Multimedia (ACMMM), 2024
- Divide-and-Conquer stategy for 2D-3D multimodal noise learning!
📺 Video Understanding
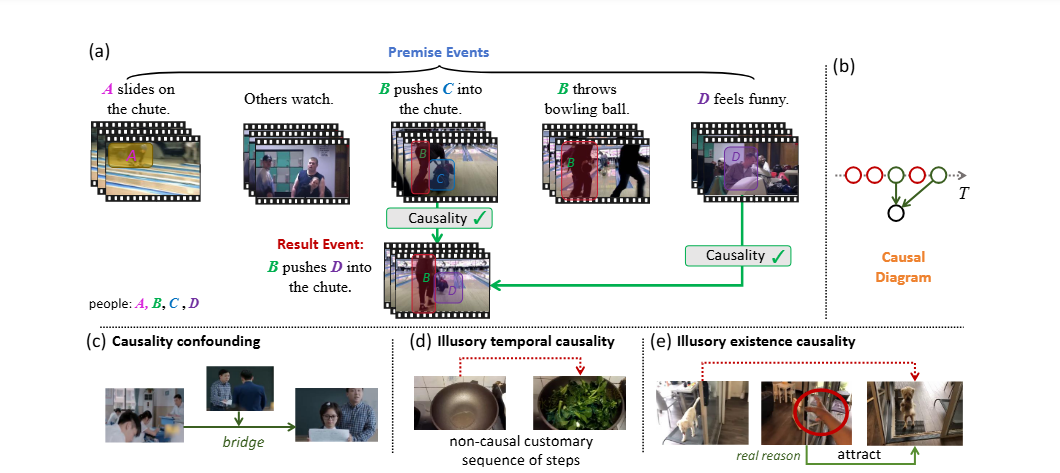
Tieyuan Chen*, Huabin Liu*, Tianyao He, Yihang Chen, Chaofan Gan, et. al
Neural Information Processing Systems (NeurIPS), Spotlight, 2024
🎓 Educations
- 2022.09 - present, PhD Candidate (Joint), Information and Communication Engineering. Shanghai Jiao Tong University.
- 2022.09 - present, PhD Candidate (Joint), Electrical and Computer Systems Engineering. Monash University.
- 2018.09 - 2022.06, Undergraduate, Software Engineering. Huazhong University of Science and Technology.
📖 Publications
- C. Gan, Y. Tu, X. Chen, T. Chen, Y. Li, M. Harandi, W. Lin, “Unleashing Diffusion Transformers for Visual Correspondence by Modulating Massive Activations”, NeurIPS 2025.
- T. Chen, H. Liu, Y. Wang, Y. Chen, T. He, C. Gan, et al, “MECD+: Unlocking Event-Level Causal Graph Discovery for Video Reasoning”, ARXIV 2025.
- G. Zou, C. Gan, CH. Lim, S. Aramvith, W. Lin, “MCA: 2D-3D Retrieval with Noisy Labels Via Multi-Level Adaptive Correction and Alignment”, ICMEW 2025.
- T. Chen, H. Liu, T. He, Y. Chen, C. Gan, et al, “MECD: Unlocking Multi-Event Causal Discovery in Video Reasoning”, NIPS 2024, Spotlight.
- C. Gan, Y. Tu, Y. Li, W. Lin, “DAC: 2D-3D Retrieval with Noisy Labels via Divide-and-Conquer Alignment and Correction”, ACMMM 2024.